

Congress just dropped a significant regulatory proposal on the AI landscape. The AI Incident Reporting Act, introduced June 25th, would require developers of high-capability AI models to report dangerous capabilities, breaches, and safety incidents to the Department of Commerce within days. Not weeks. Days.
For PMOs running portfolios packed with AI-enabled vendors, this changes the risk management picture considerably. You're no longer just tracking whether a vendor delivers on time. You're tracking whether their AI components could trigger mandatory federal reporting—and whether you'll find out before your executives read about it in the news.
The uncomfortable part? Most PMOs don't have clear visibility into which vendors use AI, let alone what happens when those systems fail.
The vendor risk blind spot just got much bigger
I watched a Fortune 500 PMO scramble when their document processing vendor had what they called a "minor configuration issue." Turned out their AI model had been misclassifying sensitive documents for three weeks. Under the proposed reporting requirements, that would have been a reportable incident. The PMO found out 47 days after it started.
This isn't really about vendors being dishonest. It's about AI incidents being fundamentally different from traditional software failures. When a database goes down, everyone knows immediately. When an AI model starts drifting or producing biased outputs, it can run for weeks before anyone notices—and the damage accumulates silently.
What makes AI vendor incidents particularly painful for portfolio delivery:
Traditional vendor failures are binary. The system works or it doesn't. Your contingency plans kick in, you activate your backup vendor, you move forward.
AI failures are probabilistic. The system keeps running but produces subtly wrong outputs. Your projects keep moving but with corrupted data, flawed analysis, or biased recommendations baked into deliverables. By the time you detect the problem, it's already woven through multiple workstreams.
A construction PMO discovered their AI-powered scheduling vendor had been systematically underestimating weather delays for two months. They'd already committed resources based on those schedules. A healthcare PMO found their AI compliance checker had been missing regulatory updates since a model refresh—three projects had gone through gate reviews with incomplete compliance assessments before anyone caught it.
Why standard vendor controls miss AI incidents
Most PMOs treat AI vendors like any other technology provider. Same risk register format. Same monthly status calls. Same SLA monitoring. This approach completely misses how AI incidents actually unfold.
Stop losing track of critical projects.
GoProjy helps you monitor, prioritize, and deliver projects on time—seamlessly.
- Unified portfolio visibility
- Real-time resource tracking
- Milestone & risk alerts
No credit card required
Take your typical vendor risk register. You've got columns for probability, impact, and mitigation. Maybe you check for SOC 2 compliance, review their disaster recovery plans, track uptime metrics. All solid practices for traditional software. Nearly useless for catching AI incidents before they become reportable events.
The core problem is detection lag. Traditional monitoring catches system outages in minutes. AI incidents hide in the outputs—a classification model gradually shifting its decision boundary, a language model hallucinating more frequently, a prediction algorithm developing demographic biases. These don't trigger alerts. They don't violate SLAs. They just quietly corrupt your project data until someone notices.
Then there's the remediation timeline problem. When a traditional system fails, you know what needs fixing. With AI incidents, you first need to figure out when the problem started. Then identify which outputs were affected. Then determine if those outputs influenced other systems or decisions. Then somehow unwind weeks or months of cascading impacts across your portfolio.
A financial services PMO discovered their vendor's risk scoring model had been incorrectly calibrated after a routine update. The fix took two hours. The impact assessment took six weeks. They had to review every project decision made using those risk scores, revalidate governance approvals, and explain to auditors why three major initiatives had proceeded based on flawed risk assessments.
Building detection mechanisms that actually work
Forget about preventing AI incidents through vendor selection alone. Even sophisticated vendors have incidents—OpenAI, Google, Microsoft have all had significant failures. Your job isn't to find perfect vendors. It's to know about incidents before they cascade through your portfolio.
Start with real discovery, not the checkbox kind where vendors self-certify their AI usage. Genuine discovery means technical architecture reviews where you map exactly which components use machine learning, what data they process, and how outputs flow into your projects.
A framework that actually surfaces AI dependencies:
Component-level mapping: Don't stop at "uses AI for document processing." Map the specific models, their training data sources, update frequencies, and output types. A vendor might use three different models—one for OCR, one for classification, one for extraction. Each has different failure modes.
Data flow tracking: Where does the AI output actually go? Into a project dashboard? Into a risk calculation? Into a resource allocation algorithm? The closer AI outputs get to decision-making, the higher your incident exposure.
Human oversight points: Does a human review AI outputs before they're used? At what frequency? With what expertise? A vendor might claim human oversight, but if it's a junior analyst spot-checking 1% of outputs monthly, that's not meaningful protection.
Prioritize mapping models that feed critical decision points first, then expand coverage.
One manufacturing PMO implemented this discovery process and found roughly 40% more AI dependencies than vendors had disclosed. More importantly, they found that six critical path projects relied on the same underlying AI service through different vendors—a single incident could have cascaded across their entire portfolio without anyone initially connecting the dots.
The three-tier monitoring system
Once you know where AI lives in your vendor ecosystem, you need monitoring that matches AI's actual failure patterns.
Tier 1: Output consistency monitoring
Track statistical properties of AI outputs over time. Not just error rates, but distribution shifts, confidence scores, and edge case frequency. When a classification model starts putting more items in the "uncertain" bucket, that's an early warning sign worth paying attention to.
-
Confidence scores clustering differently
-
Category distributions shifting beyond normal variance
-
Processing times increasing for certain input types
-
Error messages or fallback behaviors becoming more frequent
Tier 2: Cross-reference validation
Run periodic checks comparing AI outputs to alternative sources. If your vendor uses AI for cost estimation, occasionally run the same inputs through a different estimation method. Divergence beyond a threshold triggers investigation.
This doesn't mean duplicating all AI processing. Pick high-stakes outputs that directly influence go/no-go decisions, resource allocation, or compliance assessments. Check around 5-10% monthly. When divergence exceeds roughly 15%, dig deeper.
Tier 3: Incident correlation tracking
Connect vendor AI incidents to portfolio impacts. When a vendor reports any AI issue—even ones they claim don't affect you—trace the timeline through your projects. What decisions were made during that window? What deliverables were produced? What dependent work was triggered?
Build an incident impact matrix:
| Field | What to capture |
|---|---|
| Vendor name and incident date | Who reported it and when |
| Affected AI components | Which models or pipelines were involved |
| Projects using those components | All active work touching the affected system |
| Decisions and deliverables produced | Outputs generated during the incident window |
| Downstream work triggered | What was kicked off based on those outputs |
Connect vendor AI incidents to portfolio impacts. When a vendor reports any AI issue—even ones they claim don't affect you—trace the timeline through your projects. What decisions were made during that window? What deliverables were produced? What dependent work was triggered?
Contractual provisions that give you actual leverage
Your vendor contracts probably have standard language about data breaches and service failures. That won't help much with AI incidents. You need specific provisions that account for AI's unique failure modes and the proposed reporting requirements.
Incident definition expansion: Define AI incidents separately from system failures. Include model drift, training data contamination, output bias detection, and adversarial attacks. Specify thresholds that trigger notification—like confidence scores dropping below 80% or output distributions shifting beyond two standard deviations.
Notification timelines that match regulatory requirements: If the AI Incident Reporting Act passes with its 72-hour reporting window, you need vendor notification within 24 hours. Not "promptly" or "without undue delay"—specific hour counts from detection to notification.
Technical disclosure requirements: Vendors must provide technical incident details, not just executive summaries. Which models were affected? What was the root cause? What outputs were generated during the incident window? What's the confidence level that the issue is contained?
Audit and testing rights: You need the right to conduct or commission independent AI audits—actual model evaluation including bias testing, robustness checks, and adversarial testing, not just standard penetration testing.
A technology PMO rewrote their vendor contracts with these provisions and immediately got pushback from three vendors who claimed the requirements were "technically infeasible." Those same vendors later had incidents that would have been reportable under the proposed legislation. The PMO that had pushed for transparency avoided project contamination.
The rapid response playbook
When a vendor AI incident hits, every hour matters. According to Reuters, the proposed legislation would require reporting within days of discovery. That means you need a response system that moves faster than your standard risk escalation process.
Your incident response needs four parallel workstreams running simultaneously:
Workstream 1: Contamination assessment
Map every project touchpoint with the affected AI system during the incident window. This includes downstream work based on AI-influenced decisions, not just direct usage. A pharmaceutical PMO discovered an AI incident in their clinical trial site selection tool had influenced 12 other projects through resource allocation decisions.
Workstream 2: Regulatory reporting preparation
Start documenting everything immediately, assuming you'll need to report. Gather technical details, impact assessments, and remediation plans. Even if the incident doesn't meet reporting thresholds, regulators might ask questions later.
Workstream 3: Portfolio continuity planning
Activate contingency plans for affected projects. Unlike traditional failures where you switch to backup systems, AI incidents might require you to revalidate weeks of prior work. Build buffers into dependent project schedules immediately.
Workstream 4: Stakeholder communication
Craft messages for different audiences. Technical teams need details about data validity. Executives need business impact assessments. Customers might need assurance about delivery timelines. Board members want to understand regulatory exposure.
This diagram shows the rapid response workflow and how the four workstreams run in parallel with the reporting timeline.
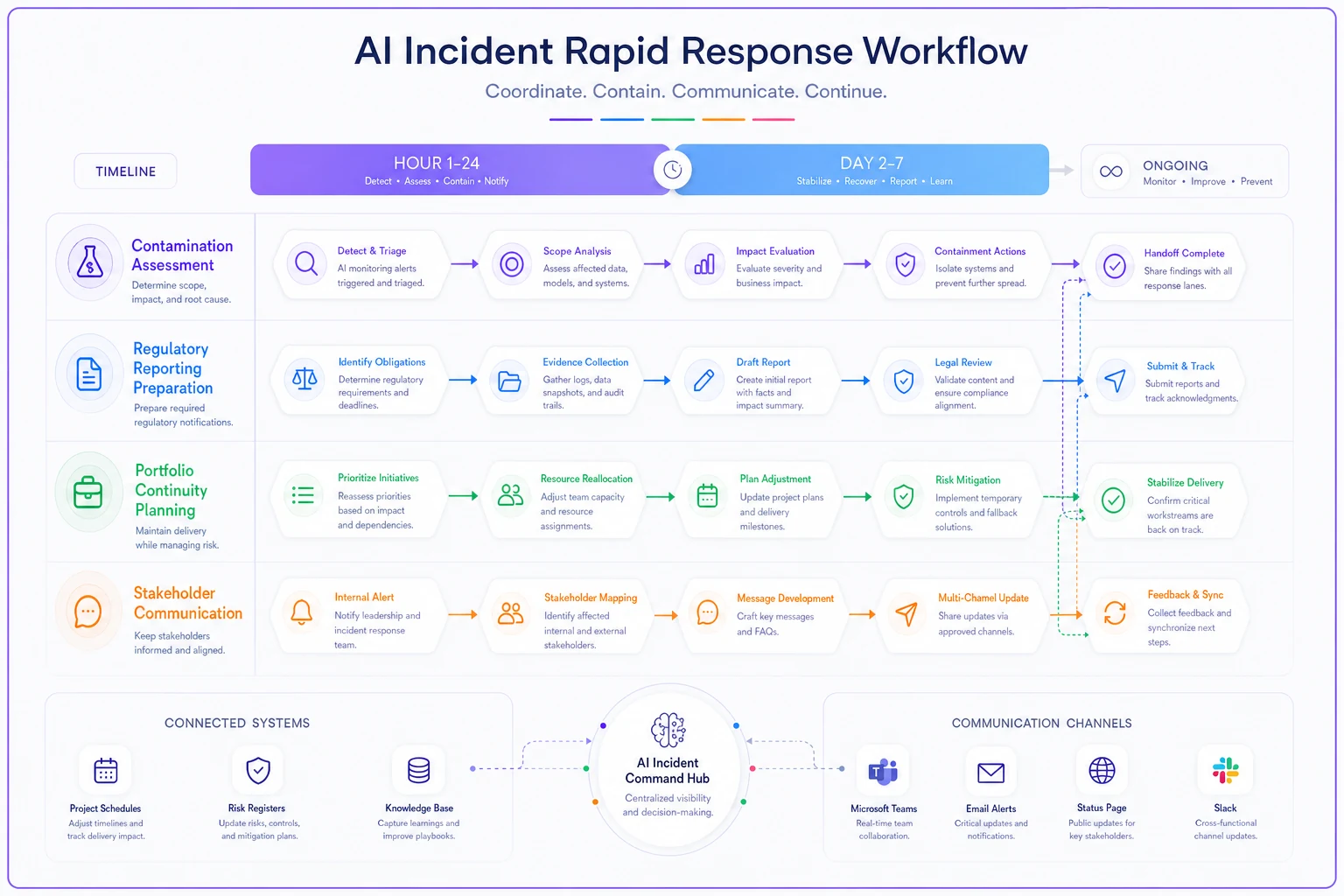
The response timeline generally looks like:
-
Hour 1-4 Initial assessment and project quarantine
-
Hour 4-8 Impact mapping and regulatory threshold evaluation
-
Hour 8-24 Stakeholder notification and contingency activation
-
Day 2-3 Deep technical assessment and remediation planning
-
Day 3-7 Portfolio rebaseline and risk register updates
Your incident response needs four parallel workstreams running simultaneously:
Reforecasting when AI breaks your assumptions
Every project baseline includes assumptions. When AI vendors have incidents, those assumptions break in ways that are hard to predict upfront. Traditional reforecasting assumes you know what broke and how long the fix takes. AI incidents create uncertainty spirals.
Consider this pattern: an AI vendor's document processing system has an incident. You estimate two weeks for remediation. Then you discover the model needs retraining with new data—another three weeks. Then you need to reprocess all documents from the incident window—another two weeks. Then downstream projects need to revalidate their work—another month. Your two-week estimate just became two months.
Build AI incident scenarios into your portfolio models:
Scenario 1: Contained failure Single model affected, clear incident window, fix doesn't require retraining. Impact: 2-3 weeks on directly affected projects.
Scenario 2: Cascading failure Multiple models affected or contaminated training data. Requires retraining and historical reprocessing. Impact: 6-8 weeks plus downstream revalidation.
Scenario 3: Systemic failure Fundamental model architecture problems or regulatory compliance issues. Requires vendor replacement or major architectural changes. Impact: 3-6 months minimum.
Run these scenarios quarterly. Identify which projects would face critical path impacts in each scenario. Build specific contingency plans for high-exposure projects. Pre-negotiate surge capacity with alternative vendors before you need it.
The PMO capability gap
Most PMOs lack the technical depth to properly assess AI risks, and that's fine—you don't need everyone to become machine learning experts. But you do need enough understanding to ask the right questions and interpret the answers.
A practical AI risk competency matrix for your PMO:
| Level | Who | What they need to know |
|---|---|---|
| Basic | All PMs | Difference between AI and traditional software failures, incident indicators, escalation triggers |
| Intermediate | Risk leads | Model performance metrics, vendor AI architectures, monitoring design |
| Advanced | AI risk specialists | Technical incident investigations, model testing evaluation, regulatory interfaces |
Invest in training, but be realistic about timelines. You won't build deep AI expertise overnight. Consider contracting specialist advisors for vendor assessments and incident response. A retail PMO brought in an AI audit firm quarterly to review their vendor ecosystem. The cost was meaningful but nowhere near what they avoided by catching issues early.
Early warning integration
This connects directly to your existing early warning systems for schedule slippage. AI incidents create distinct slippage patterns—sudden productivity drops in AI-assisted tasks, quality issues requiring rework, or validation delays while confirming output integrity.
Modify your slippage triggers to catch AI-related delays:
-
Unusual rework patterns in AI-dependent tasks
-
Validation tasks taking longer than baseline
-
Sudden drops in AI-assisted task completion rates
-
Increased manual override frequency
These patterns often show up before anyone knows there's an AI incident. They're your early signal that something's off in the vendor's system, even when they haven't reported anything yet.
The governance gate problem
Your stage gates assume deliverables are valid. AI incidents put that assumption at risk in a way that's hard to catch through standard quality checks—a deliverable produced using contaminated AI outputs might look completely fine but be fundamentally flawed.
Add AI integrity checks to your gate reviews:
-
Were any AI systems used to produce this deliverable?
-
Were those systems incident-free during the production window?
-
Has the output been validated against non-AI sources?
-
What's the confidence level in the AI-generated components?
Don't make these checkbox exercises. Require actual evidence. A consulting PMO added AI integrity attestations to their gate reviews and caught three deliverables in the first quarter that would have passed traditional quality checks but contained AI-contaminated analysis. That's not a theoretical win—that's three projects that didn't need to be rolled back mid-execution.
Building portfolio resilience
The goal isn't to eliminate AI from your vendor ecosystem—it provides too much operational value to abandon. The goal is building portfolio resilience that maintains delivery momentum even when AI incidents occur.
Start with concentration risk. If multiple projects depend on the same AI vendor, a single incident creates portfolio-wide exposure. Diversify your AI vendor base, but do it thoughtfully. Having ten vendors with shallow capabilities and poor incident response actually creates more risk than three vendors with mature processes.
Create vendor tiers based on incident preparedness:
| Tier | Description | Where to use them |
|---|---|---|
| Tier 1 | Demonstrated incident response, transparent reporting, rapid remediation | Critical path work |
| Tier 2 | Basic incident processes, improving transparency, reasonable remediation timelines | Important but buffered work |
| Tier 3 | Limited incident visibility, developing processes, uncertain remediation | Experimental or non-critical applications only |
Route work accordingly and revisit these tiers at least twice a year. Vendors move between tiers based on how they handle actual incidents, not just their written policies.
Where operational software helps
Manual incident response can't realistically match the speed requirements of AI incident reporting. You need automated detection, assessment, and coordination working together.
Modern AI-powered operational platforms handle a lot of the heavy lifting here—continuously monitoring vendor outputs for statistical anomalies, automatically mapping contamination paths through your portfolio, generating regulatory reports with complete audit trails, and coordinating response teams across workstreams. The key is integration. Your incident response system needs to connect to your vendor management, risk registers, project schedules, and communication channels. When an incident hits, you need everything moving in parallel, not sequential email chains and manual updates across disconnected tools.
Looking ahead
The AI Incident Reporting Act might not pass in its current form. But the regulatory direction is clear—AI incidents will become regulated events requiring rapid response and formal reporting. PMOs that build these capabilities now will have a real advantage when requirements arrive.
Start with the basics. Map your AI vendors. Build detection mechanisms. Update your contracts. Create response playbooks. Train your teams. Even rudimentary AI incident management beats the "hope nothing happens" approach that most PMOs currently follow.
The organizations that handle AI-enabled operations well won't be the ones that avoid AI risks entirely. They'll be the ones that detect, respond, and adapt faster. When AI incidents become reportable events, PMOs with mature incident management will keep delivering while others are still trying to understand what happened.
Your portfolio's resilience depends on decisions made now. Every month of delay increases both regulatory and delivery risk. The question isn't whether you'll face an AI vendor incident—it's whether you'll be ready when you do.
Ready to elevate your project delivery?
Join over 2,500 project teams using GoProjy to optimize resources, reduce risks, and drive portfolio success.